
Влияние на потерю данных и на незапланированные простои
Реальность современного мира такова: потеря данных оказывает серьезное влияние на бизнес и его прибыль. Предприятия несут прямые и косвенные затраты из-за незапланированных простоев и потери данных, включая затраты, связанные с:
- потерей производительности сотрудников;
- упущенным доходом;
- потерей репутации, что снижает доверие и лояльность клиентов, что может привести к потере возможностей для дальнейшего ведения бизнеса;
- потерянным временем, потраченным на устранение проблемы: время, которое ИТ-отделы тратят на восстановление данных, то есть это время, которое ИТ-специалисты уже не потратят на другие жизненно важные задачи. А иногда компаниям приходится нанимать внешних консультантов, чтобы помочь им «восстановиться», что увеличивает расходы.

Растущие проблемы защиты данных
Перебои в работе сети электропитания, сбой компонентов серверного оборудования, человеческие ошибки или злонамеренность персонала, повреждение данных, ошибки программного обеспечения, сбои на объектах и стихийные бедствия — список обширен, но представляет собой лишь несколько источников простоя приложений и потери данных. А в нынешних условиях в наше стране они экспоненциально растут и предугадать их становиться все труднее и труднее и ИТ персонал изо всех сил пытается оградить себя хоть как-то от этих угроз.
Необходимость защиты данных от меняющегося ландшафта угроз становится еще более сложной из-за экспоненциального роста объема данных на 35–45 % в год. Учитывая рост и распространение данных, неудивительно, что ИТ специалистам сложно создать последовательный план защиты данных, охватывающий все критически важные данные.
Одновременно с этим, все больше и больше данных имеют решающее значение для операций в компании. Многие компании теперь имеют данные, для которых требуется доступность 24x7x365. Это означает, что требования к соглашению об уровне обслуживания (SLA) в отношении таких данных и времени безотказной работы приложений меняются. Вы больше не можете думать о требованиях к доступности в виде часов или дней для многих приложений, данных и рабочих нагрузок и теперь ИТ отделам приходится думать за «минуты» или «секунды». При этом устаревшая инфраструктура с неадекватными моделями защиты данных и аварийного восстановления (DR) не может удовлетворить этим требованиям, что, конечно, только усложняет общую задачу защиты данных.
Проблемы защиты данных в гибридном мире
Могут ли предприятия позволить себе потери доходов и производительности, связанные со сбоями в работе технологий? На сильно конкурентном рынке немногие компании могут это сделать. Многие ИТ отделы рассчитывают решить проблему простоев бизнеса, просто переместив рабочие нагрузки в облако: они предполагают, что их облачный провайдер/гиперскейлер реплицирует данные компании в своих облачные центры как нечто само собой разумеющееся и будут надежно хранить их там. Но на самом деле поставщики облачных услуг берут на себя ответственность только за базовую инфраструктуру. Они не могут сосредоточиться на инфраструктуре, не гарантируют защиту облачных данных в случае сбоя или катастрофы-без дополнительных сервисов. Короче говоря, ИТ отделам по-прежнему приходится предпринимать множество шагов для защиты своих данных и приложений в облаке.
Желаемые результаты по защите данных от случайной потери
ИТ-специалистам самим или с помощью системных интеграторов, например таких, как Лантек, необходимо преодолеть эти проблемы и сформулировать стратегию защиты данных, которая сможет защитить их от множества вышеперечисленных проблем. Например, ИТ отделам часто нужны способы защиты данных, чтобы в случае сбоя какого-либо оборудования или даже всего сайта они не потеряли очень много данных. С другой стороны, специалистам, отвечающим за резервное копирование, необходимо сохранять данные в течение более длительных периодов времени с возможностью восстановить эти данные на какое-то время назад. Таким образом, они смогут «перемотать время назад», если поймут, что файл был поврежден, удален или неправильно изменен.
Так же ИТ-отделам нужны эффективные и простые решения, которые не только защищают данные от многих типов потерь, но и охватывают сложные среды клиентов. Решениям может потребоваться охватывать несколько сайтов и работать в гибридной локальной и облачной среде.
Наконец, планы восстановления играют жизненно важную роль в любом плане защиты данных. Если компании действительно сталкиваются с потерей данных, им необходимо как можно быстрее восстановить свои данные, чтобы можно было возобновить нормальную работу.
Потребности клиентов в защите данных
Еще имеется немаловажный аспект, почти вызов для ИТ отделов - защита и безопасность данных. Под защитой данных понимается любая форма защиты данных от потери или повреждения, а под безопасностью данных понимается защита данных от несанкционированного доступа и использования. Хотя защита данных и безопасность не являются синонимами, их часто рассматривают вместе. Хороший план защиты данных должен также включать положения о безопасности данных.
Безопасность данных опирается на три основных столпа. ИТ-специалистам необходимо контролировать, кто может получить доступ к данным. Им часто приходится шифровать данные, чтобы предотвратить их чтение неавторизованными пользователями. И им, возможно, придется контролировать суверенитет этих данных или, другими словами, контролировать, где они хранятся.
Правило 3-2-1 или 3-2-1-1-0
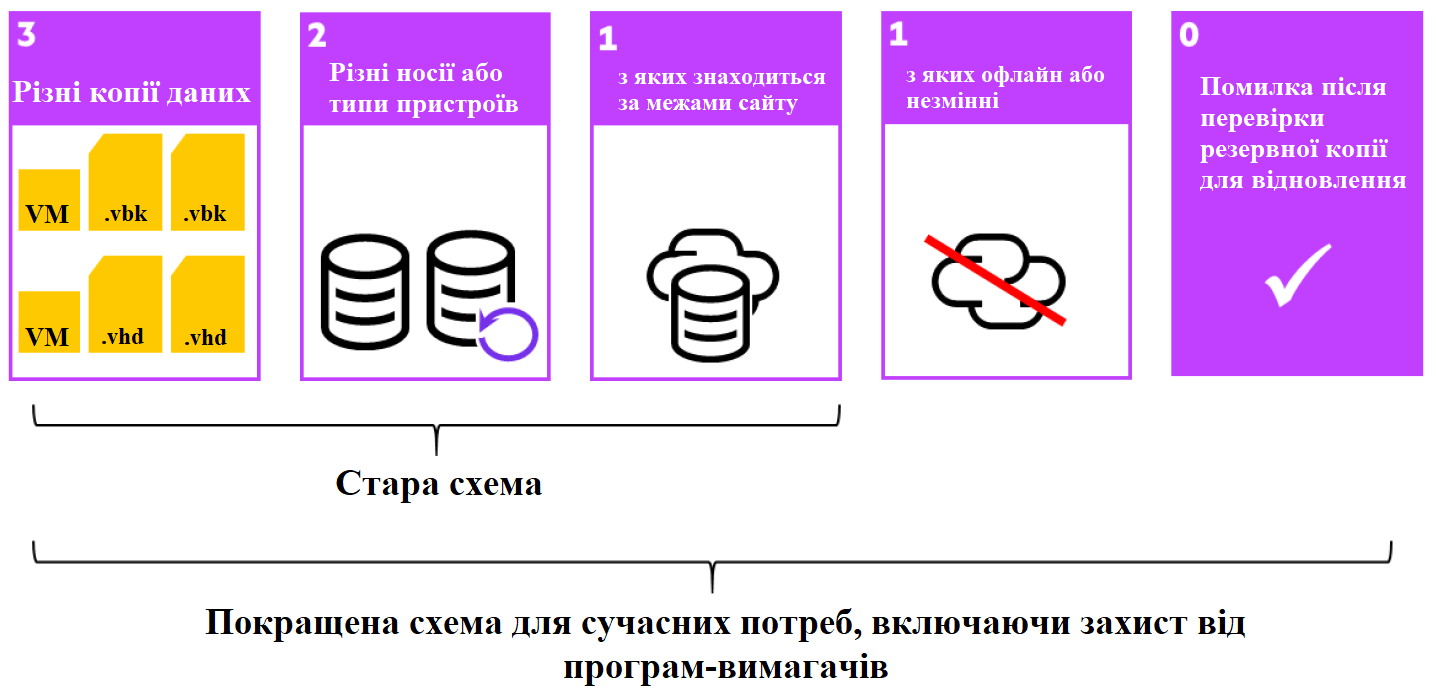
И мы постепенно перешли к самому главному-механизмам/схемам защиты данных. Для этого рассмотрим схему 3-2-1, которая давно признана лучшей практикой защиты данных. Однако в последнее время набирает популярность и улучшенная схема- 3-2-1-1-0.
Данное правило требует от компаний хранить как минимум «3» копии данных. Обычно рабочая копия считается первой, и у ИТ специалистов должно быть как минимум две резервные копии. Однако некоторые компании считают, что это правило означает, что им необходимы три резервные копии. Цифра «2» в правиле указывает, что резервные копии хранятся как минимум на двух разных носителях или типах устройств. Например, клиент может хранить одну резервную копию на вторичной системе хранения данных (SAN массиве), а другую — на ленте. Первая цифра «1» в правиле означает, что хотя бы одна из этих резервных копий должна находиться за пределами офиса/сайта. Например, компании могут хранить ленту в другом офисе. Или они могут реплицировать резервную копию на другой сайт или в облако. В любом случае ИТ отделу обязательно нужна эта удаленная копия, чтобы противостоять потенциальным катастрофам.
Однако программы-вымогатели расширили требования. Вторая цифра «1» в правиле требует, чтобы хотя бы одна из резервных копий была автономной или неизменяемой. Это требование может, но не всегда, перекрываться с предыдущим требованием. Другими словами, у ИТ отдела может быть одна копия, находящаяся за пределами офиса, и другая копия, находящаяся в автономном режиме или неизменяемая. Или можно хранить одну резервную копию, которая находится как вне офиса, так и в автономном режиме. Цифра «0» правила подчеркивает важность тестирования. ИТ специалисты должны протестировать свои резервные копии и убедиться, что их можно восстановить без ошибок.
Таким образом, правило 3-2-1-1-0 ясно дает понять, что надежные планы защиты данных зависят не только от количества резервных копий; но и от того, где и как хранятся резервные копии. Не имеет значения, что ИТ отдел имеет три отдельные резервные копии, хранящиеся на одном сайте, если ракета, землетрясение, наводнение или другое стихийное бедствие разрушит этот сайт, то все три резервные копии мгновенно исчезнут. Планы аварийного восстановления требуют от ИТ отделов «сохранить» — другими словами, отправить за пределы офиса — по крайней мере одну резервную копию критически важных данных. ИТ специалисты могут физически переносить данные в другое место; они могут скопировать данные на съемные носители, например, на ленту или оптический носитель, а затем физически транспортировать этот носитель в другое место. Или они могут использовать вторичные системы хранения данных (SAN массивы), что означает отправку данных по сети. В любом случае ИТ отделы могут управлять процедурами хранения самостоятельно или поручить их сторонним специалистам, например нам ?
Варианты передачи данных за пределы офиса
Перемещение резервных копий за пределы офиса/сайта является основной характеристикой «защищенного неизменяемого хранилища». У ИТ персонала есть несколько вариантов соблюдения автономной/неизменяемой части правила 3-2-1-1-0. Они могут хранить резервную копию на съемном носителе в автономном режиме (с воздушным зазором) в физически безопасном месте. Иногда хранение резервной копии невозможно или ИТ персоналу нужен более быстрый доступ к резервной копии. В этом случае можно сделать копию неизменяемой. Лента предлагает опцию «Write Once, Read Manу (WORM) или однократная запись и многократное чтение», что означает, что однажды записанные данные не могут быть изменены. Многие поставщики облачных хранилищ также предоставляют неизменяемые параметры. Например, ИТ специалисты могут настроить хранилище HPE StoreOnce Catalyst и сделать его неизменяемыми.
Важность тестирования резервных копий
В итоге резервные копии делаются для того, чтобы при необходимости их можно было использовать. Крайне важно, чтобы специалисты, отвечающие за резервное копирование, тестировали свои резервные копии, чтобы убедиться в отсутствии ошибок. Лучшая проверка резервной копии — восстановление из нее данных. Например, если вы выполняете резервное копирование виртуальных машин, вам следует проверить возможность восстановления виртуальных машин. Вы можете запланировать ежемесячные тесты, в ходе которых вы будете восстанавливать виртуальные машины на серверах, сопоставимых с теми, на которых пользователи фактически восстанавливают виртуальные машины. В идеале включите виртуальные машины, убедитесь, что ОС запускается и виртуальные машины доступны. Также убедитесь, что виртуальные машины могут запускать нужные службы. Программное обеспечение для резервного копирования и восстановления может также включать функции проверки резервных копий, которые вы можете использовать, например Veeam и Commvault.
Пример использования правила
ИТ отделы могут выполнить правило 3-2-1-1-0 разными способами. Рисунок ниже иллюстрирует лишь один из примеров:
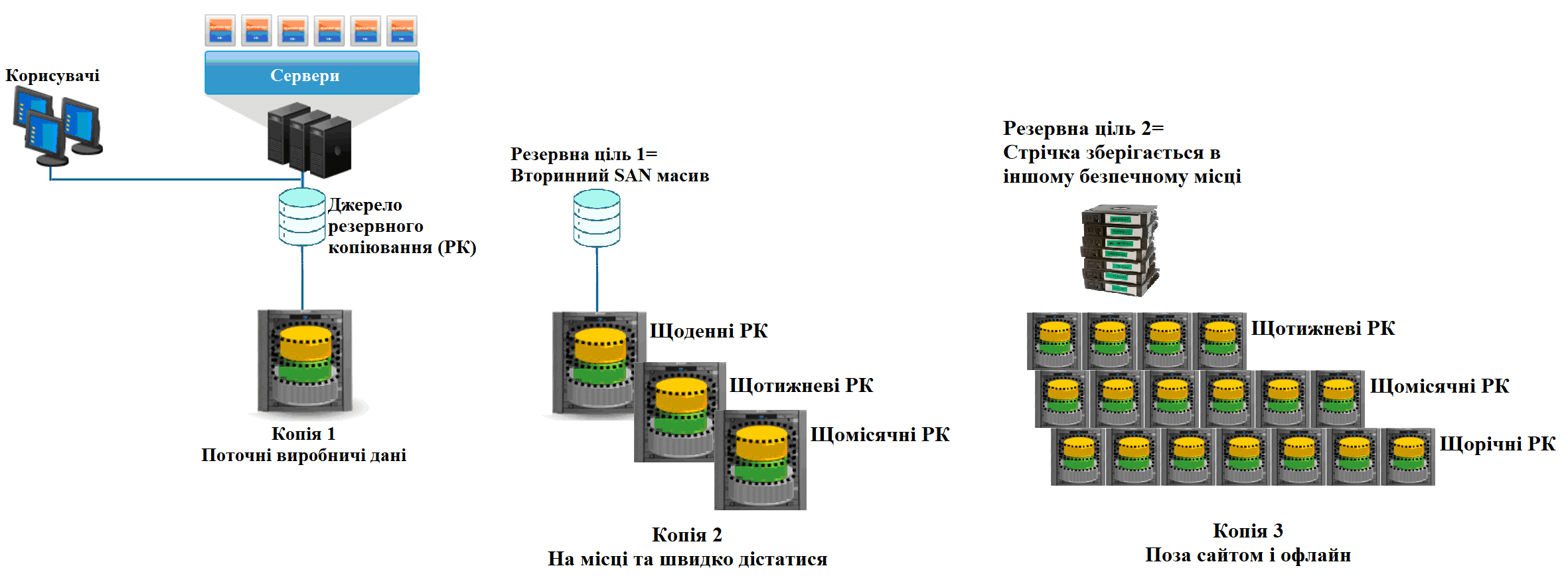
В этом примере производственными данными является Копия 1. Затем планируется ежедневное, еженедельное и ежемесячное резервное копирование на дополнительный SAN массив (вторичный). На SAN массиве сохраняются несколько различных резервных копий. Это Копия 2. Эти данные доступны на случай, если они понадобится для быстрого восстановления. Также выполняется еженедельное, ежемесячное и ежегодное резервное копирование на ленту. Для этого перемещаются эти ленты в безопасное место за пределами офиса/сайта. Это Копия 3. Эта копия также соответствует требованиям для работы вне офиса и в автономном режиме.
Итоги
Что происходит, когда в важнейших бизнес-системах происходят сбои? В эпоху, когда победителей и проигравших определяет постоянная доступность, простои сложных, взаимосвязанных рабочих нагрузок, ориентированных на клиентов, могут нанести непоправимый, а иногда и катастрофический ущерб с финансовой и деловой точки зрения. Помимо упущенной выгоды, реальная стоимость простоя может включать в себя испорченную репутацию, утрату доверия и лояльности клиентов, ослабление конкурентной позиции и даже нарушение нормативных требований. В сегодняшнем мире, управляемом социальными сетями, новость об отключении электроэнергии или сбое и недоступности сервиса компании быстро становится вирусной, и могут потребоваться годы, чтобы устранить этот ущерб. Согласно отчетам независимых аналитиков, незапланированные простои обходятся предприятиям в среднем в 88 000 долларов всего за один час. Поэтому очевидно, что ИТ специалисты очень заинтересованы в устранении пробелов в защите и защите своих данных и услуг. А для этого необходимо иметь продуманную стратегию резервного копирования и строго соблюдать рекомендации по устранению внештатных ситуаций с данными, которые может порекомендовать системный интегратор, например компания Lantec.
Автор статьи - Михаил Федосеев, архитектор инфраструктурных решений Lantec.