
В одной из предыдущих статей мы детально рассказывали, как можно создавать отказоустойчивое решение используя одну из функций систем хранения данных HPE Peer Persistence, которое реализовано на HPE Alletra 5000/6000 и HPE Nimble. Это законченное решение, предназначенное для приложений, которым необходимы обеспечить показатели отказоустойчивости, которые стремятся к нулю: целевая точка восстановления (RPO) и целевое время восстановления (RTO), используя при этом синхронную репликацию с автоматическим переключением (automatic switchover). Это все отлично работает и просто настраивается.
Но есть у компании HPE и такие системы хранения как HPE Primera и HPE Alletra 9000 и как у этого модельного ряда обстоят дела с подобным отказоустойчивым решением? Оказывается, такое решение есть, оно даже еще интереснее и называется - HPE Active Peer Persistence.
В отличие от классического решения HPE Peer Persistence, которое позволяет только первичной системе хранения в решении обслуживать ввод-вывод для выделенных томов (virtual volume) в группе удаленного копирования (remote copy group), настроенной для синхронной репликации (synchronous replication); то HPE Active Peer Persistence позволяет использовать как первичную, так и вторичную системы хранения в HPE Active Peer Persistence Remote Copy для обслуживания запросов ввода-вывода приложений для виртуальных машин. То есть HPE Active Peer Persistence позволяет сделать решение еще более интересным и выгодным и которое будет балансировать нагрузку серверного ввода-вывода между двумя системами хранения для виртуальных томов. Этот сервис также поддерживает общие кластерные решения для виртуальных томов (virtual volume), которые требуют максимальной доступности, позволяя серверам в кластере отправлять ввод-вывод в обе системы хранения.
Подключение серверов к обеим системам хранения в решении является обязательным и гарантирует прозрачное восстановление после сбоя. Эта конфигурация также гарантирует, что серверы будут по-прежнему иметь доступ к своим данным с нулевым RPO и нулевым RTO для широкого спектра потенциальных сбоев.
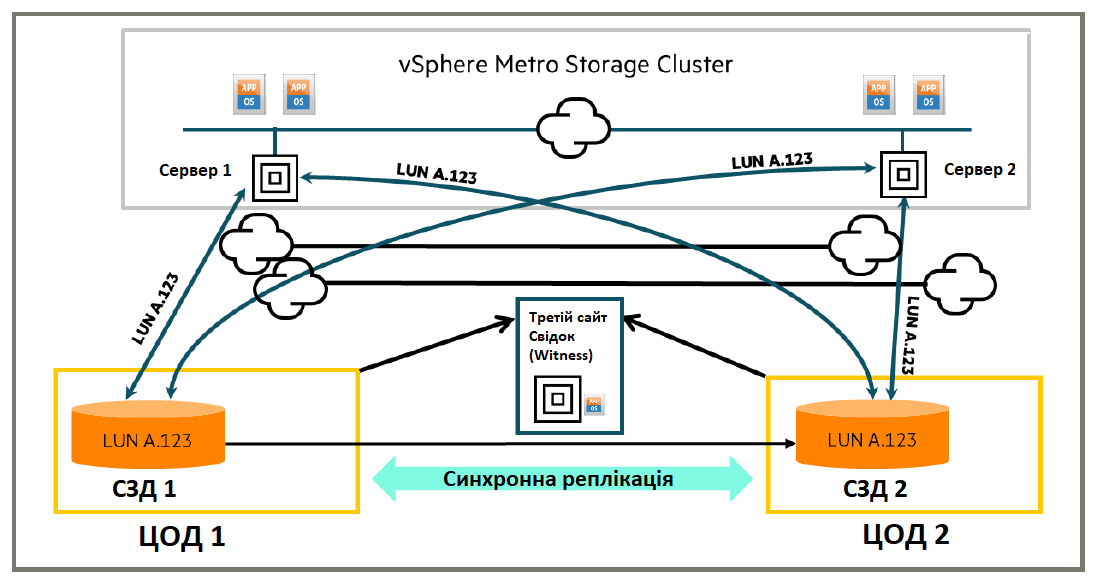
этом все пути к обеим системам хранения активны для всех серверов, использующих группу HPE Active Peer Persistence. Сервер может отправлять запросы ввода-вывода в любую из систем хранения, но желательно, чтобы серверы отправляли ввод-вывод только в ту систему, к которой он находятся в непосредственной близости, а не посылали ввод-вывод в систему на удаленную площадку, при этом имея дополнительную задержку («длинный неоптимизированный путь»). Это достигается путем указания того, является ли путь сервера к системе хранения «оптимизированным» путем (наименьшая задержка) или «неоптимизированным» путем (более высокая задержка). Предполагается, что сервер будет использовать оптимизированные пути; если оптимизированные пути недоступны, то в этом случае он будет использовать свои не оптимизированные пути. Термины «оптимизированный» и «неоптимизированный» в отношении путей сервера к системам хранения относятся к состояниям пути ALUA (Asymmetric Logical Unit Access), установленным на пути.
Для HPE Active Peer Persistence состояние пути ALUA следующие:
• Активный оптимизированный ALUA: активный путь, предпочтительный для запросов ввода-вывода сервера. Ожидается, что путь будет использоваться сервером, если он доступен. Он должен иметь наименьшую задержку от сервера до системы хранения.
• ALUA активный неоптимизированный: активный путь, являющийся альтернативным путем для запросов ввода-вывода сервера. Этот путь следует использовать только в том случае, если активные оптимизированные пути недоступны. Активные неоптимизированные пути обычно имеют значительно большую задержку от сервера и до системы хранения.
• ALUA недоступен: путь недоступен, и серверный ввод-вывод не может быть отправлен по пути. Пути к вторичной системе хранения становятся недоступными, если группа удаленного копирования остановлена или какие-либо виртуальные тома в группе не синхронизированы.
Администратор систем хранения сам сможет определить, является ли путь оптимизированным или неоптимизированным, при настройке HPE Active Peer Persistence. Это позволяет серверам, которые находятся в разных центрах обработки данных (ЦОД1 и ЦОД2), но совместно используют виртуальные тома в группе удаленного копирования (например, для vSphere Metro Storage Cluster), отправлять ввод-вывод только в систему хранения, к которой они находятся в непосредственной близости. Это так же позволяет избежать дополнительной задержки, связанной с отправкой операций ввода-вывода на удаленную систему хранения, как это может произойти с классическим одноранговым сохранением. Независимо от того, находится ли сервер рядом с первичной системой или вторичной для HPE Active Peer Persistence, ожидается, что время отклика ввода-вывода группы удаленного копирования (чтение и запись) будет одинаковым для ввода-вывода, отправляемого в локальную систему хранения.
Как HPE Active Peer Persistence, так и классическая HPE Peer Persistence предназначены для прозрачного восстановления (с показателями RPO = 0 и RTO = 0) после сбоев систем хранения. Как HPE Active Peer Persistence, так и классическая HPE Peer Persistence прозрачно восстанавливаются после следующих сценариев сбоев:
• Сбой системы хранения данных: если система хранения в конфигурации HPE Active Peer Persistence дает сбой, уцелевшая система при необходимости берет на себя управление группой удаленного копирования и обслуживает все операции ввода-вывода.
• Сбой канала репликации: первичная система хранения продолжает обслуживать ввод-вывод. Никакие данные не реплицируются в/из вторичной системы хранения. При использовании HPE Active Peer Persistence пути ALUA к вторичной системе хранения становятся недоступными, а все операции ввода-вывода хоста направляются в первичную систему хранения для группы HPE Active Peer Persistence.
В дополнение к этим сбоям HPE Active Peer Persistence прозрачно восстанавливается после сбоев, от которых не восстанавливается классическое решение HPE Peer Persistence:
• Отключение физического сервера (сервер теряет все подключения к своей оптимизированной системе хранения): сервер, который теряет подключение к своим активным оптимизированным путям и будет использовать свои активные не оптимизированные пути.
• Перезагрузка/отключение основной системы хранения: происходит автоматический прозрачный сбой (automatic transparent failure), и вторичная система хранения становится основной для всех групп HPE Active Peer Persistence Remote Copy.
Универсальность данных решений заключается еще в том, что можно настроить переключение данных технологий из HPE Peer Persistence в HPE Active Peer Persistence и наоборот без перезагрузки систем хранения и прерывания работы приложений. Так же одновременно на системах хранения можно использовать как HPE Active Peer Persistence, так и HPE Peer Persistence.
HPE Active Peer Persistence в системах хранения HPE Alletra 9000 и HPE Primera — это значительное улучшение по сравнению с классическим продуктом HPE Peer Persistence. Благодаря возможности обслуживать ввод-вывод сервера для томов в группе удаленного копирования из обоих систем хранения в решении HPE Peer Persistence, HPE Active Peer Persistence обеспечивает значительное снижение общей задержки ввода-вывода для кластерных файловых систем, различных баз данных и различных приложений по сравнению с классическим HPE Peer Persistence. Благодаря этим преимуществам, а также лучшей доступности и простоте управления по сравнению с классическим решением HPE Peer Persistence мы рекомендуем разворачивать и использовать именно HPE Active Peer Persistence.
Автор статьи – Михаил Федосеев, архитектор инфраструктурных решений Lantec.