
Настав новий 2026рік, а разом із ним — звичні відкладені рішення: подбати про здоров’я, читати більше книжок, можливо, нарешті розібратися з постійно зростаючим обсягом електронних листів. Але для керівників технологічних компаній це не лише час особистого вдосконалення — це час переосмислення того, як розкрити бізнес-цінність накопиченої інформації. У 2026 році й надалі пріоритетною залишається одна ключова задача: підготувати свою стратегію роботи з даними до використання ШІ.
Погляньмо правді в очі: дані — це життєва сила сучасного бізнесу, але без надійної інфраструктури це все одно що готуватися до марафону, поїдаючи пончики перед телевізором. Стрімкий розвиток ШІ чітко показав, що традиційні системи зберігання даних — «пилові сховища» та «розрізнені озера» — стримують розвиток організацій. У цьому році головне — створити масштабовану, безпечну та гнучку стратегію роботи з даними, яка не просто йде в ногу з ШІ, а й прискорює його впровадження.
За прогнозами GlobalData, вже цього року обсяг глобальних даних перевищить вражаючі 175 ЗБ (зетабайт). Значна частина цих даних, ймовірно, складатиметься з неструктурованої інформації — зображень, відео та текстів. ШІ розвивається саме завдяки такому різноманіттю, але лише за умови, що ваша стратегія обробки даних здатна з ним впоратися. На жаль, багато організацій і досі використовують застарілі системи, розроблені для роботи з електронними таблицями, а не з нейронними мережами.
Усі ми пам’ятаємо dial-up доступ до інтернету: повільний, незграбний і абсолютно не відповідний сучасним потребам. Саме так виглядають застарілі системи зберігання даних у світі, яким керує ШІ. Традиційні сховища не були розраховані на величезну пропускну здатність, різноманіття та швидкість сучасних навантажень ШІ. Більше того, вони ледве справляються з підтримкою напівструктурованих і неструктурованих даних — саме тих типів інформації, якими «живиться» штучний інтелект.
На додачу до цього, розпорошеність інформації в різних сховищах робить практично неможливим отримання необхідних аналітичних даних. Передбачалося, що «озера даних» виправлять ситуацію, але на практиці вони часто перетворюються на «болота даних» — неорганізовані, недоступні та переповнені вузькими місцями в продуктивності.
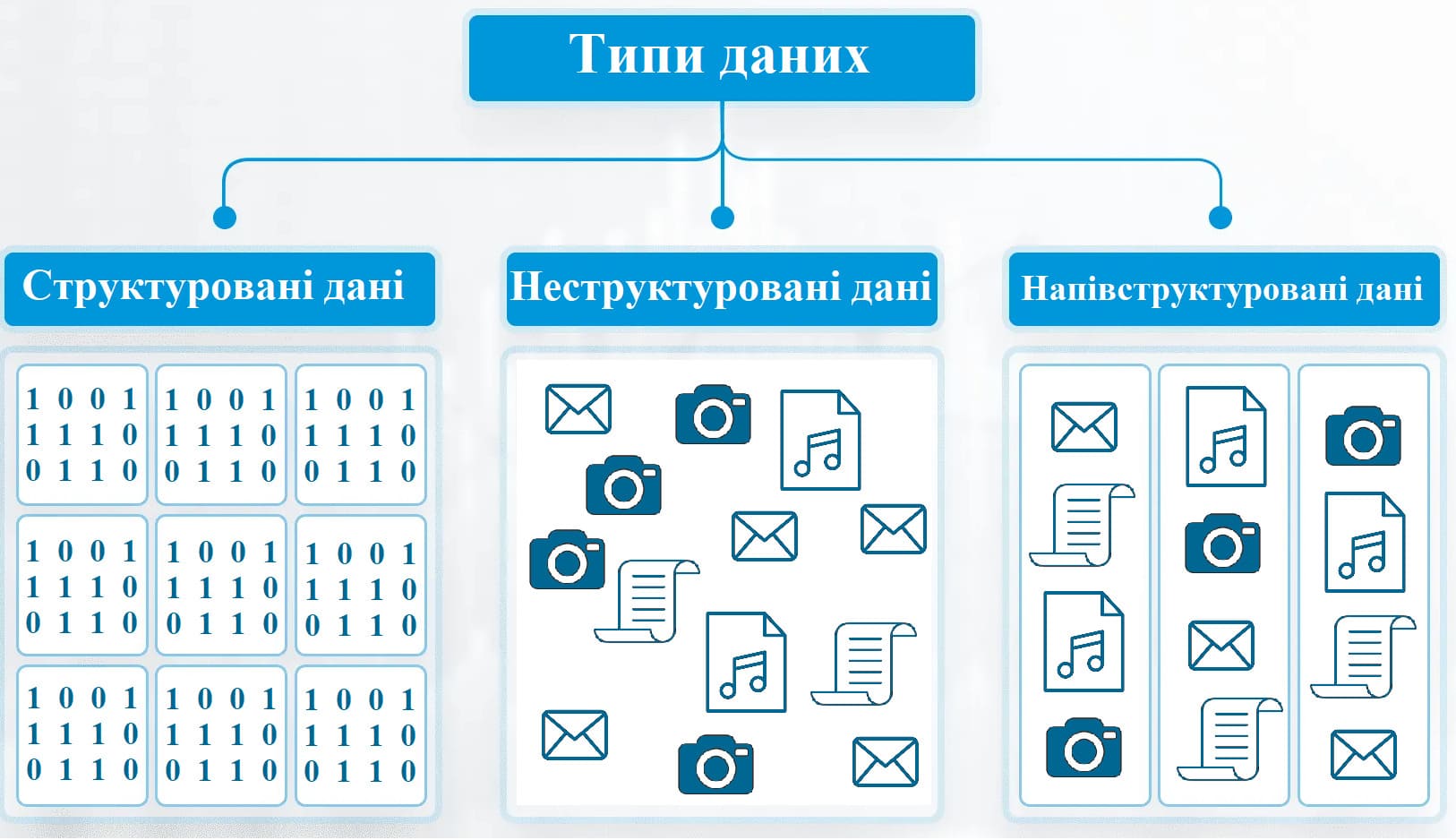
Тепер трохи теорії: що таке структуровані та неструктуровані дані — дві широкі категорії інформації, що збирається. Структуровані дані — це дані, які ідеально вписуються в таблиці та містять дискретні типи, такі як числа, короткий текст і дати. Неструктуровані дані погано піддаються табличному представленню через великий обсяг або специфічний характер. До них, наприклад, належать аудіо- та відеофайли, а також великі текстові документи. Іноді навіть числові або текстові дані можуть бути неструктурованими, якщо їх неможливо ефективно подати у вигляді таблиці. Наприклад, дані з датчиків є безперервним потоком числових значень, але створення таблиці з двома стовпцями (мітка часу та значення датчика) є неефективним і непрактичним. І якщо рішення для структурованих даних давно відомі та добре вивчені, то що робити, коли потрібні рішення для зберігання й обробки неструктурованих даних?
Далі мова піде про рішення від компанії HPE, яке чудово вирішує всі викладені вище завдання та проблеми — HPE Alletra Storage MP X10000.
HPE Alletra Storage MP X10000 — це унікальна програмно-визначена, дезагрегована, горизонтально масштабована система зберігання даних для робочих навантажень, пов’язаних із неструктурованими даними, створена компанією HPE з нуля. Вона поєднує високопродуктивний сервіс об’єктного зберігання (а згодом і файлового) та екзабайтну ємність із доступністю й відмовостійкістю корпоративного рівня. Це унікальне рішення для зберігання неструктурованих даних, побудоване на базі єдиної апаратної платформи HPE Alletra Storage MP та кероване через хмару HPE GreenLake, що забезпечує інтуїтивно зрозумілий хмарний інтерфейс з уніфікованим управлінням.
Це рішення можна розгорнути як локально «на землі», так і в хмарі (або кількох хмарах). Воно базується на контейнерній архітектурі з оркестрацією на основі Kubernetes. Платформа від початку у своїй архітектурі підтримує кілька протоколів для уніфікованого доступу до даних. Наразі підтримується об’єктне сховище на базі S3 (із підтримкою AWS та MinIO S3), а в майбутніх релізах з’явиться вбудована підтримка файлових сервісів. Завдяки дезагрегованій архітектурі обчислювальні потужності та ресурси зберігання можна масштабувати незалежно для конкретних робочих навантажень: до 8 двоконтролерних нод (надалі в планах — до 16) і до 12 ПБ (надалі — до приблизно 50–80 ПБ). Це рішення оптимізоване для SSD-дисків, тобто є повністю all-flash системою. Компанія HPE прагне забезпечити вищу продуктивність, ніж у конкурентів, за рахунок розподілу контейнера S3 між кількома вузлами/нодами. Ще однією важливою перевагою, пов’язаною з продуктивністю, є можливість запускати об’єктні та файлові сервіси без пріоритету одного над іншим і, відповідно, без «пригнічення» другого.
Далі коротко описуються архітектурні елементи рішення HPE Alletra Storage MP X10000.
Апаратна архітектура
Рішення HPE Alletra Storage MP X10000, як зазначалося вище, використовує дезагреговану апаратну архітектуру, що надає низку переваг для сучасних компаній. Такий підхід забезпечує гнучкість, ефективність та відмовостійкість, гарантуючи адаптацію інфраструктури зберігання даних до мінливих потреб бізнесу, зокрема:
- незалежне масштабування продуктивності та ємності;
- високу ефективність зберігання навіть за невеликих масштабів завдяки використанню твердотільних накопичувачів NVMe із застосуванням технології захисту даних erasure coding;
- стійкість до багаторазових відмов контролерів і передбачувану продуктивність у разі збою;
- спрощену систему, що не потребує масштабних оновлень обладнання з виходом контролерів наступного покоління.

Основою рішення HPE Alletra Storage MP X10000 є стандартний апаратний корпус HPE Alletra Storage MP
(детальніше: https://lantec.ua/news/hpe-greenlake-for-block-storage-mp-pochatok-eri-sistem-zberigannya-novogo-pokolinnya).Обчислювальний корпус HPE Alletra Storage MP являє собою шасі стандартної висоти 2U, яке містить два контролери в задній частині корпусу. Окремий дисковий корпус 2U для накопичувачів має 24 посадкові місця для підключення SSD NVMe по двох портах. Кожне шасі включає блоки живлення з резервуванням і модуль виявлення шасі (CDM), що спрощує взаємодію між шасі та полицями розширення, а також допомагає налаштовувати систему. Сама система HPE Alletra Storage MP X10000 може складатися з кількох шасі/корпусів HPE Alletra Storage MP, кожен із яких може бути або «обчислювальним», або «дисковим».
Контролерні вузли-ноди
Кожен контролерний вузол оснащений односокетним процесором, 512 ГБ пам’яті DDR та 4 слотами PCIe для адаптерів. Одні слоти призначені для підключення до внутрішньої мережі та містять 2-портові адаптери 100 Гбіт/с. Ці порти підключаються до комутаторів, що формують внутрішню фабрику системи, забезпечуючи зв’язок усіх контролерних вузлів між собою та з усіма дисковими корпусами. Інші два слоти PCIe використовуються для звичайного мережевого трафіку й можуть містити або 2-портові адаптери 100 Гбіт/с, або 4-портові адаптери 10/25 Гбіт/с (адаптери FC у цьому рішенні не передбачені!). Усі контролерні вузли в усіх обчислювальних корпусах системи HPE Alletra Storage MP X10000 утворюють кластер високої доступності, при цьому всі вузли мають доступ до всіх дисків, розміщених у JBOF. HPE Alletra Storage MP X10000 підтримує мінімум 3 вузли-ноди (корпус із 1–2 контролерами), а на даний момент підтримується максимум 16 контролерів (корпуси з 8 вузлами-нода ми).
Корпуси для дисків — JBOF
Кожен корпус оснащений односокетним процесором, 64 ГБ пам’яті DDR та одним двопортовим 100 Гбіт/с PCIe-адаптером, виділеним для підключення внутрішніх компонентів. У дисковому корпусі відсутня можливість підключення зовнішніх серверів до модулів введення-виведення. HPE Alletra Storage MP X10000 підтримує мінімум 1 і максимум 8 корпусів для дисків. Корпуси повинні містити 24 накопичувачі однакової ємності. Підтримуються твердотільні накопичувачі TLC NVMe ємністю 1,92 ТБ, 3,84 ТБ, 7,68 ТБ, 15,36 ТБ і 30,72 ТБ, а також QLC NVMe ємністю 15,36 ТБ, 30,72 ТБ і 61,44 ТБ. Дані розподіляються по всіх 24 дисках у корпусі з використанням механізму erasure coding із потрійною парністю — це означає, що система може витримати до 3 відмов дисків у корпусі.
Внутрішні Ethernet-комутатори
Контролерні вузли HPE Alletra Storage MP X10000 та модулі введення-виведення для корпусів накопичувачів підключені через пару 32-портових комутаторів 100 Гбіт/с. Увесь трафік між вузлами-нода ми та дисковими корпусами, а також будь-який міжвузловий трафік проходить через ці комутатори. Такий дезагрегований підхід забезпечує незалежне масштабування продуктивності та ємності на рівні окремих вузлів і корпусів накопичувачів, а також критично важливу стійкість до збоїв обладнання.
Підключення до зовнішніх мереж
Рішення HPE Alletra Storage MP X10000 використовує розширені можливості підключення до зовнішніх мереж для забезпечення оптимальної продуктивності та масштабованості в корпоративних середовищах. Для задоволення різноманітних потреб сучасних підприємств HPE Alletra Storage MP X10000 підтримує кілька варіантів високошвидкісного підключення до зовнішніх мереж, зокрема: 10, 25 і 100 Гбіт/с. Ці варіанти забезпечують гнучкість вибору пропускної здатності, що відповідає конкретним вимогам робочих навантажень, гарантуючи безперебійну передачу даних і зниження затримок. Для підтримання високої доступності та збалансованої продуктивності в кластері зберігання даних HPE Alletra Storage MP X10000 має призначений пул IP-адрес зовнішніх мереж, які перетворюються на кінцеву точку S3 із використанням round-robin DNS-балансування. Цей метод рівномірно розподіляє вхідні запити між призначеними IP-адресами та вузлами кластера, запобігаючи перетворенню окремого вузла на вузьке місце та підвищуючи загальну надійність і ефективність системи.
Розділи обслуговування даних (DSP)
Розділи обслуговування даних (DSP) є ключовим компонентом архітектури HPE Alletra Storage MP X10000, забезпечуючи гнучке та збалансоване за навантаженням управління даними й метаданими, що зберігаються в системі. Постійний стан DSP (усі дані та метадані) повністю зберігається на внутрішніх дисках у спільному пулі зберігання. Фрагменти цього пулу, які називаються RAID-групами, динамічно виділяються DSP залежно від використовуваної ємності DSP.
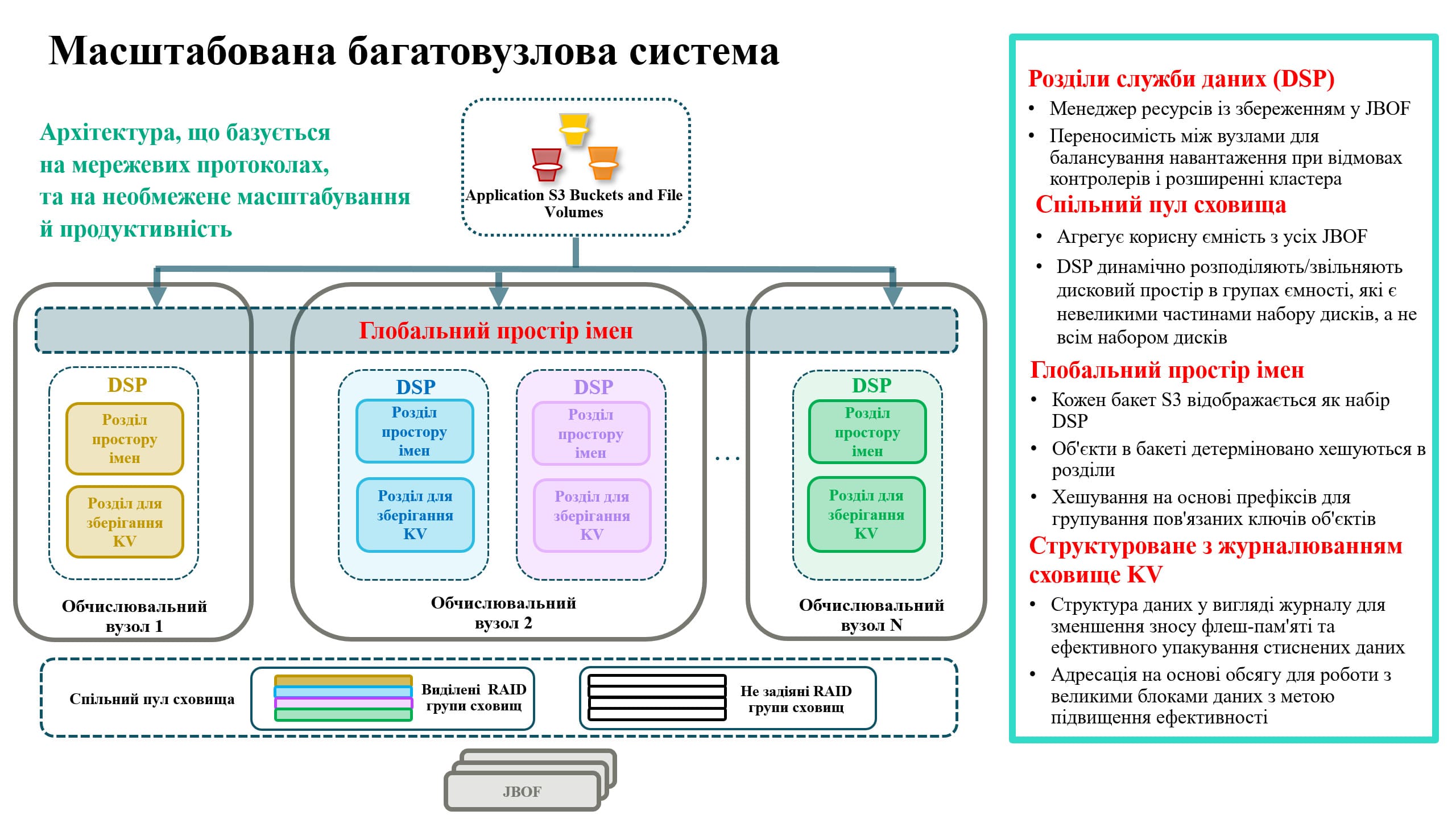
DSP працюють на вузлах контролера та рівномірно розподілені між вузлами кластера. Оскільки самі вузли не відстежують стан, а всі вузли мають доступ до повного глобального простору імен і пулу зберігання, DSP є портативними та можуть легко й швидко переміщуватися на інші вузли у разі відмови одного з них. Це гарантує постійну доступність даних і метаданих, що належать DSP.
Загальний пул зберігання
Кожен із SSD NVMe-накопичувачів, що входять до складу дискових корпусів, розділений на невеликі логічні диски, які називаються «дисклетами». Ці дисклети формують RAID-групи, розподілені по бекенду. Таким чином створюється загальний пул зберігання, доступний без обмежень для всіх вузлів кластера через єдиний глобальний простір імен, що забезпечує ефективне, високонадійне та масштабоване зберігання. Загальний пул дозволяє DSP динамічно розподіляти та вивільняти RAID-групи за потреби, забезпечуючи раціональне використання ємності. Фоновий «збір сміття» в SSD-дисках звільняє простір, повертаючи його до загального пулу. Щоб забезпечити роботу контролерних вузлів без збереження стану та уникнути необхідності в постійному кеші, частина бекенд-сховища використовується як буфер запису RAID із потрійною парністю. Більшість невеликих операцій запису можуть спочатку фіксуватися в буфері, підтверджуватися, а потім асинхронно переноситися до сховища ключ-значення (KV) із лог-структурою пакетами.
Сховище ключ-значення з лог-структурою
Рішення використовує сховище ключ-значення (KV) із лог-структурою, створене для використання переваг дезагрегованої архітектури та all-flash-зберігання. Таке сховище є основою для рівнів протоколів зберігання, реалізованих поверх нього. Дані та метадані додаються до журналу, а KV-сховище зіставляє фрагмент даних або метаданих із його розташуванням у журналі. Структура журналу мінімізує зростання обсягу запису, підвищуючи загальну ефективність використання SSD-дисків. Вона базується на екстентах — безперервних областях зберігання, що підвищує продуктивність, знижує накладні витрати на метадані та покращує ефективність стиснення. Завдяки використанню конструкції на основі KV-сховища рішення може бути оптимізоване як для TLC-, так і для QLC-дисків. Ефективність ємності ґрунтується на стисненні даних і підтримці erasure coding із потрійною парністю (в межах одного масиву). Для сценаріїв резервного копіювання, з метою захисту даних, із можливістю до 60-кратного скорочення їх обсягу, швидкістю роботи до 1,2 ПБ/год і значним підвищенням продуктивності, можна використовувати інтеграцію зі шлюзом HPE StoreOnce 7720. При цьому інтеграція з HPE StoreOnce VSA також залишається підтримуваною.
Безпека
HPE Alletra Storage MP X10000 має розширені функції безпеки на рівні обладнання, ОС та управління, забезпечуючи захист платформи, зокрема:
- підтримку протоколу TLS 1.3;
- шифрування на базі TPM-модуля;
- безпечний тунель mTLS із взаємною автентифікацією сертифікатів для підключення до консолі управління DSCC;
- управління доступом на основі ролей (RBAC) і управління привілейованим доступом (PAM).
Основні сценарії застосування
- ШІ та машинне навчання (RAG, LLM, GPUDirect for S3, RDMA);
- аналітика великих даних у реальному часі;
- підтримка критично важливих бізнес-застосунків (99,9999%);
- резервне копіювання та відновлення;
- зберігання неструктурованих даних;
- гібридні та хмарні середовища (HPE GreenLake, Ezmeral Data Fabric).
Висновки
Оскільки підприємства продовжують масштабуватися та генерувати неструктуровані дані безпрецедентними темпами, надзвичайно важливо впроваджувати перспективні рішення, здатні не лише відповідати зростаючим вимогам епохи штучного інтелекту та машинного навчання, а й надавати цінну інформацію про дані для покращення бізнес-результатів. Використовуючи архітектурні основи, описані в цій статті, ви зможете ефективно спроєктувати та розгорнути рішення HPE Alletra Storage MP X10000 для вирішення бізнес-завдань на ринку неструктурованих даних. В Україні вже є таке сховище, яке буде розгорнуте в комплексному рішенні для фабрики ШІ.