
У наших попередніх статтях ми розповідали про саму платформу HPE SimpliVity, а також про те, як внутрішні механізми цієї платформи дозволяють захищати дані від втрати. У цій статті розказано про можливі сценарії збоїв обладнання, які стоять на двох ЦОД, і як цим збоям запобігають без втрати даних.
Трохи теорії. Кластер HPE SimpliVity у більшості інсталяцій будують на одному фізичному майданчику (ЦОД 1), але його за бажанням можна «розширити/розтягнути» на два фізичні майданчики (ЦОД 2), якщо ці два майданчики з'єднано між собою з високою пропускною спроможністю (10 Гбіт/с) і малою затримкою, зазвичай менше ніж 2 мс RTT (у деяких випадках цей показник може бути не таким жорстким, із більш «лояльною» затримкою).
До появи функції розширеного кластера (Stretched Cluster) для ЦОД з двома або більше нодами HPE SimpliVity завжди використовував рішення HPE SimpliVity Storage HA. Тобто, коли сервер-нода виходить з ладу (наприклад, через оновлення firmware, переведення в режим обслуговування або банальний системний збій «заліза»), інший у тому самому ЦОД бере на себе послуги оброблення даних і дає змогу продовжувати обслуговувати віртуальні машини.
Розтягнуті кластери (stretched cluster) забезпечують ще більший захист: обслуговування триває навіть у разі збоїв кількох нод HPE SimpliVity у серверній шафі в одному з ЦОД. Розтягнутий кластер HPE SimpliVity - це рішення для забезпечення безперервності бізнесу (business continuity), час відновлення після відмови якого вимірюється секундами. Це забезпечується завдяки використанню так званих зон доступності, які являють собою фізично суміщені сукупності сіверів-нод, що визначені як такі, що мають ймовірність спільного збою через зовнішні сили. Налаштувавши рівну кількість хостів у двох зонах доступності (наприклад, 8+8) і встановивши Арбітра на іншому майданчику, не втратить доступ до даних у разі втрати зони (фактично ЦОД).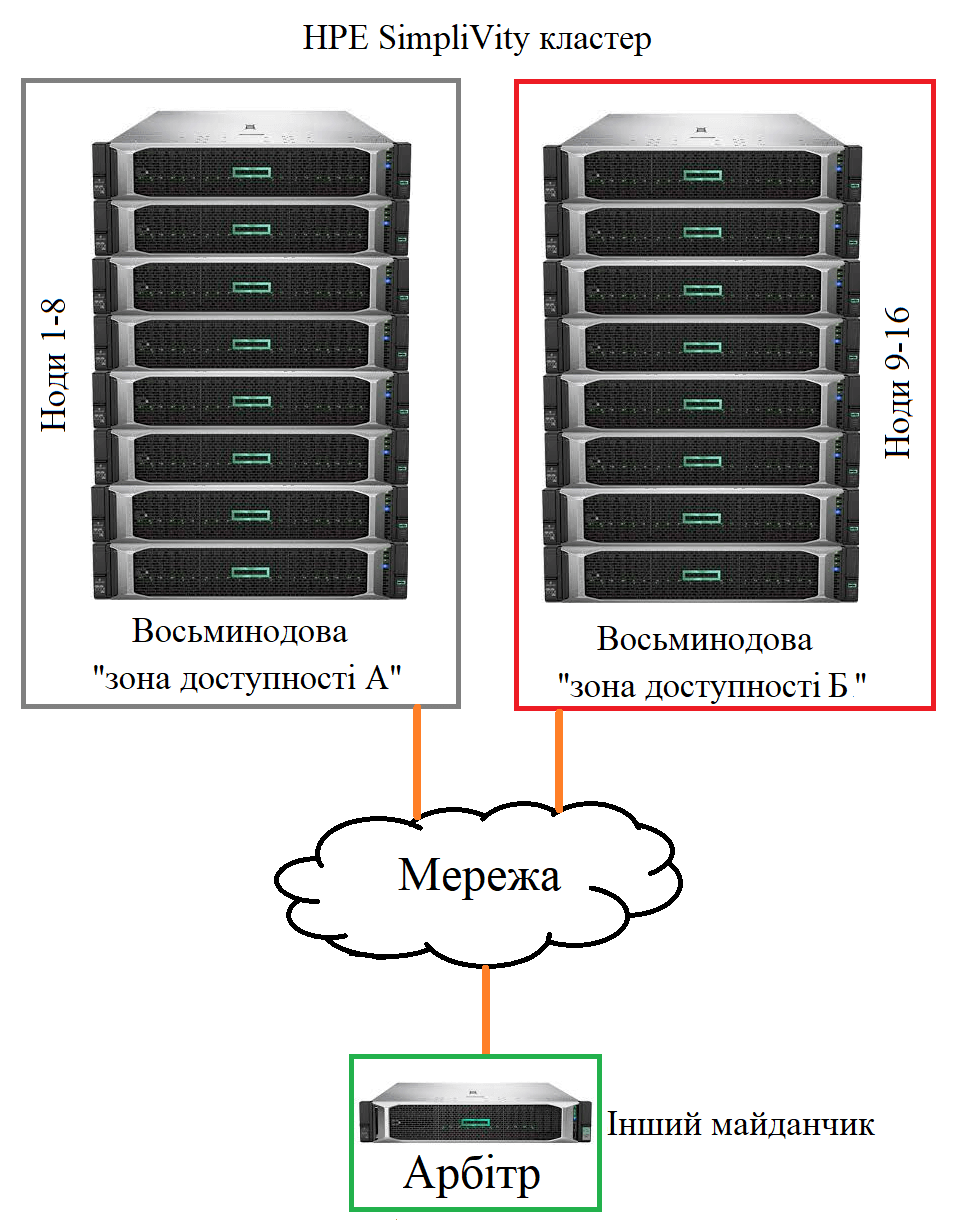
Топологія розширеного кластера HPE SimpliVity
Сценарії збоїв із зонами доступності
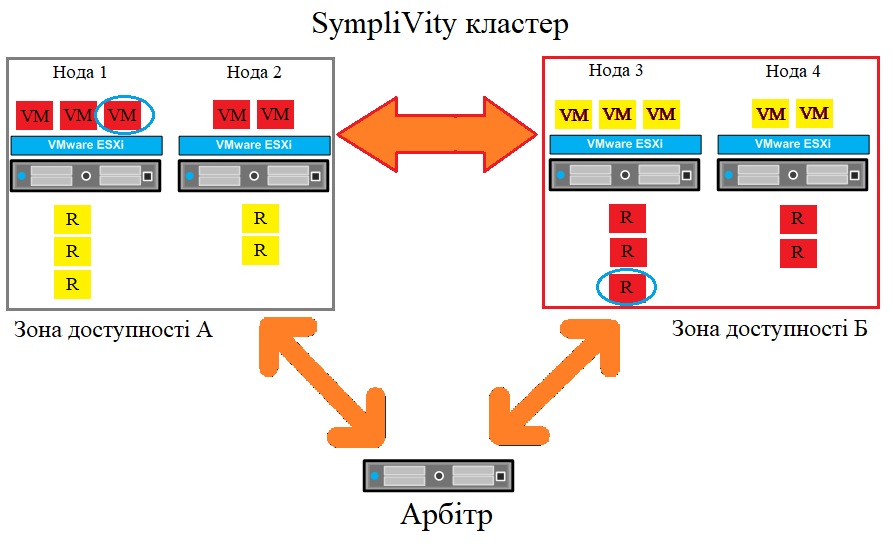
Початкове налаштування розширеного кластера
Розтягнуті кластери можуть захистити робочі навантаження в разі збоїв різних компонентів. Налаштування, представлене в цьому прикладі, спрощене, але дає хороший огляд функціональності розширеного кластера. Наша початкова установка складається з одного логічного ЦОД з одним кластером. Налаштовано дві зони доступності А і Б, у кожній з них по дві ноди. На кожній ноді розташовується кілька віртуальних машин. Кожна віртуальна машина має свою репліку (R), що зберігається в інших зонах доступності. Арбітр розташований на іншому об'єкті, щоб уникнути можливого сценарію поділу кластера.
У цій конфігурації допускаються такі збої:
- Один або обидва лінки до Арбітра не працюють.
- Збій зв'язку між зонами доступності.
- Один хост виходить з ладу.
- Одна зона доступності виходить з ладу.
Сценарій відмови: втрата зв'язку з Арбітром
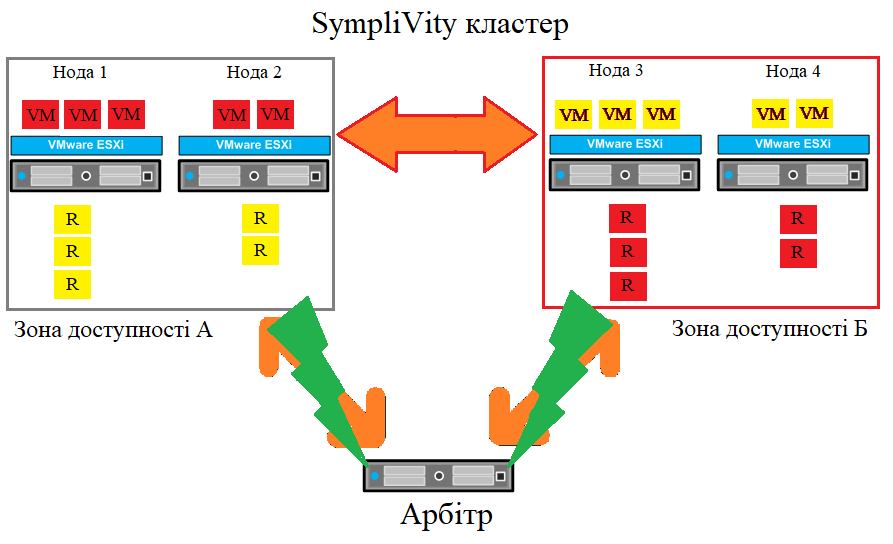
Розтягнутий кластер із втратою зв'язку з арбітром
У першому сценарії зв'язок між Арбітром і зоною доступності А втрачається. Обидві зони доступності, як і раніше, можуть бачити одна одну. Це означає, що кворум, як і раніше, зберігається і всі операції триватимуть у звичайному режимі. Якщо відбувається одночасний збій мережевого з'єднання між Арбітром і зоною доступності Б, це нічого не змінює, оскільки обидві зони доступності, як і раніше, бачать одна одну, кворум зберігається і всі операції тривають. Висновок такий: втрата самого Арбітра або втрати зв'язку між Арбітром і зоною доступності не впливає на робоче навантаження.
Сценарій відмови: зв'язок між зонами доступності втрачено
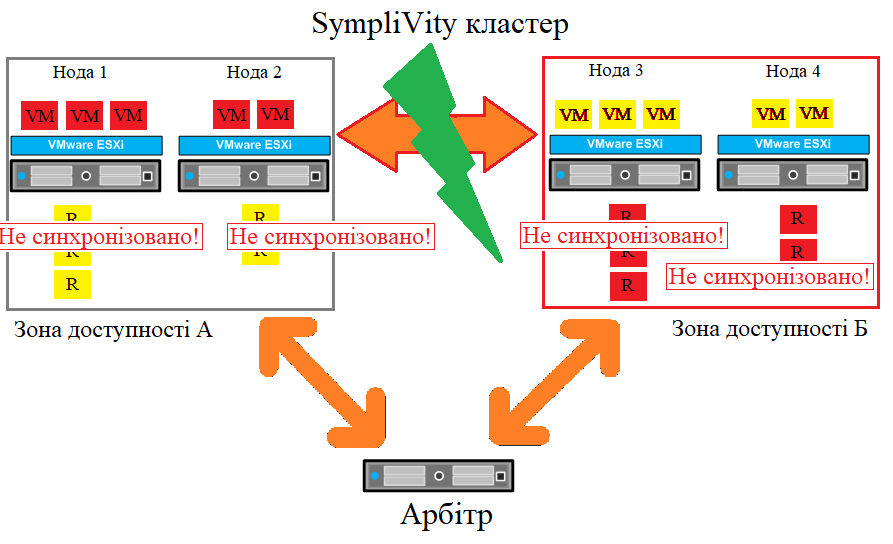
Втрачено з'єднання між зонами доступності в розтягнутому кластері
Якщо мережеве з'єднання між зонами доступності втрачено, але кожна із зон доступності, як і раніше, зможе бачити Арбітра. Це означає, що кворум зберігається і всі операції віртуальної машини тривають. Негативним впливом цього збою є втрата високої доступності сховища. Навіть якщо сховище високої доступності втрачено, усі віртуальні машини, як і раніше, захищені RAID. Коли зв'язок між зонами доступності буде відновлено, віддалені репліки автоматично відновлять високу доступність сховища.
Сценарій відмови - відмова ноди
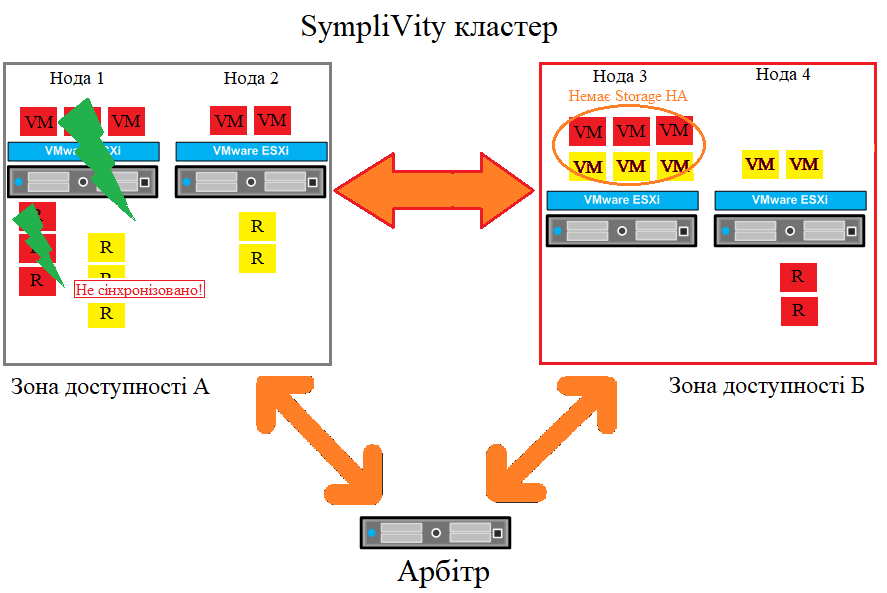
Збій однієї ноди в розширеному кластері
У разі збою однієї ноди HPE SimpliVity в певній зоні доступності кворум зберігається за розтягнутим кластером, а всі інші віртуальні машини (окрім тих, які працюють на ноді, що вийшла з ладу) працюють. Постраждалі віртуальні машини перезапускаються на нодах в іншій зоні доступності. Вони більше не перебувають у стані високої доступності сховища, але як і раніше захищені RAID. Коли нода повертається, висока доступність сховища відновлюється, і ці віртуальні машини можна перенести автоматично або вручну на вузол, що вийшов з ладу, за допомогою VMware vSphere vMotion.
Сценарій відмови: повна відмова зони доступності
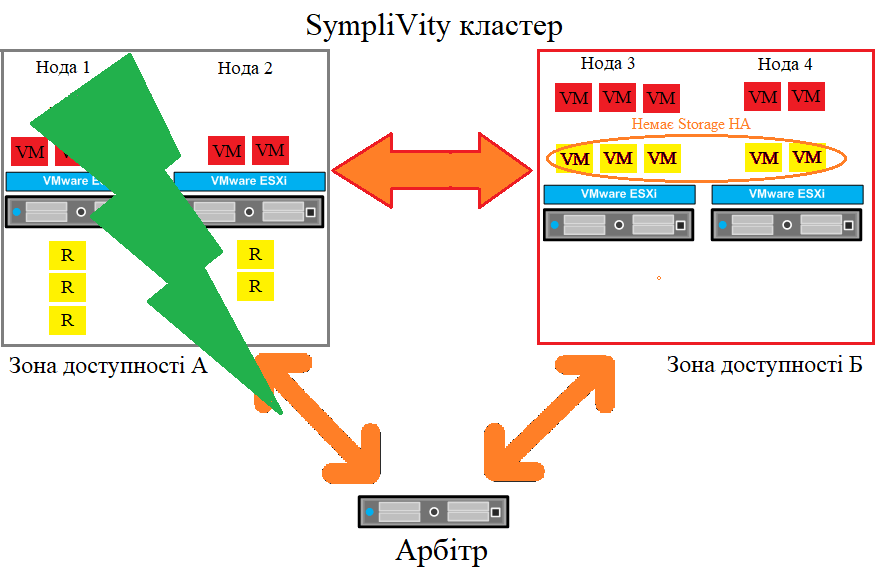
Збій зони доступності в розширеному кластері
Якщо одна із зон доступності вийде з ладу, зона доступності, що залишилася, однаково зможе підключитися до Арбітра, а це означає, що кворум залишиться на місці. Якщо в зоні доступності A станеться збій, усі віртуальні машини в зоні доступності Б залишаться без змін. Віртуальні машини із зони доступності A будуть перезапущені в зоні доступності Б і більше не перебуватимуть у сховищі високої доступності, але, як і раніше, будуть захищені RAID. Коли зона доступності A повертається, висока доступність сховища відновлюється, а віртуальні машини, які раніше працювали в зоні доступності Б, можна перенести автоматично або вручну назад у зону доступності A за допомогою VMware vSphere vMotion.
І останнє. Щоб усе це працювало так, як описано вище, необхідно суворо дотримуватися таких правил:
- На всіх нодах має бути встановлена підтримувана версія програмного забезпечення HPE SimpliVity.
- На всіх нодах має використовуватися підтримувана версія VMware ESXi.
- Усі вузли HPE SimpliVity мають належати до одного кластера високої доступності (HA).
- У ЦОД 1 і ЦОД 2 повинні підводитися незалежні ресурси електроживлення і зв'язку.
- Максимальна затримка туди і назад на міжсайтовому каналі 10 Гбіт/с не може перевищувати 2 мс.
- Розміщення Арбітра в третьому фізичному місці.
Автор статті - Михайло Федосєєв, архітектор інфраструктурних рішень Lantec.